前言
最近爆火的DeepSeek-TUI被社区戏称为“DeepSeek 版 Claude Code”。它是由美国独立开发者Hunter Bown开发的一个开源项目(而非 DeepSeek 官方产品),旨在为开发者提供一个原生适配deepseek家族模型的AI Agent。它的优势在:
原生百万级上下文 (1M Token):一键配置,傻瓜式接入,用户只需在初始化时输入API-key即可开始体验。
对运行环境0依赖:采用Rust语言编写并打包的二进制文件,不依赖node/Python运行时。
亲和的适配:作者(被称为“鲸鱼哥”)虽然是外国人,但非常重视中国开发者。他专门准备了中文README,并将 Release 包托管在阿里云、腾讯云上,解决了国内下载 GitHub 慢的问题。
但该项目当前存在一个致命的问题——缓存命中率极低。根据我的实测,实际命中率只有50%左右,直接导致的后果就是,同样的token消耗量,可能带来10倍的费用差距。
还原现场
我将以Claude Code作为对照组,让Agent来修复DeepSeek-TUI项目Issues中的一个问题。
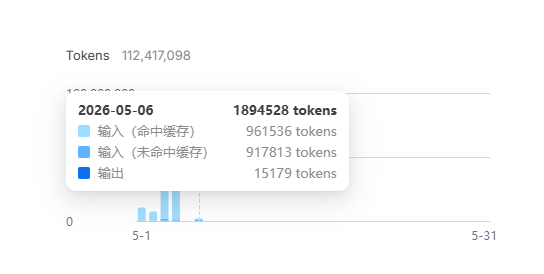
首先使用DeepSeek-TUI,让Agent获取Issues列表,再让它分析#872这个问题,这是一个Windows终端编码错误导致显示乱码的问题。最终得到如下tokens消耗:
接下来是Claude Code登场,执行相同的任务后,消耗情况如下:
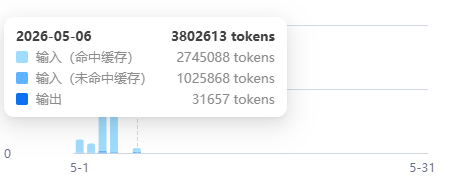
综合计算可得出缓存命中率是94.3%(Claude Code)v.s. 50.8%(DeepSeek-TUI)。
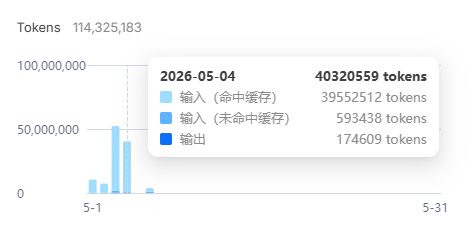
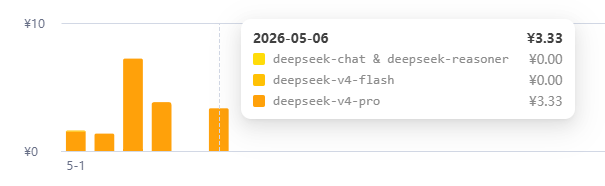
这个差异带来的直接结果就是05-06这一天token消耗(400w)的费用直逼05-04消耗(4000w)的费用。
原因分析
根据我的观察,DS-TUI生成的session文件中,每次的工具调用中出现了动态字段,如:
"id": "call_00_ywEmpH62X63h1t1hufYL0638"这样动态变化的字段插入上下文时直接导致了deepseek的缓存机制失效,大量token只能走“缓存未命中”的高费路线。
简单概述Prefix Matching: 从第 0 个 Token 开始的连续匹配,只有完全一致的内容才会触发命中。
接下来我进一步调用了Claude Code扫描项目,它告诉我,我这样的想法只是表象,核心还是该Agent的上下文构建机制不够优秀。
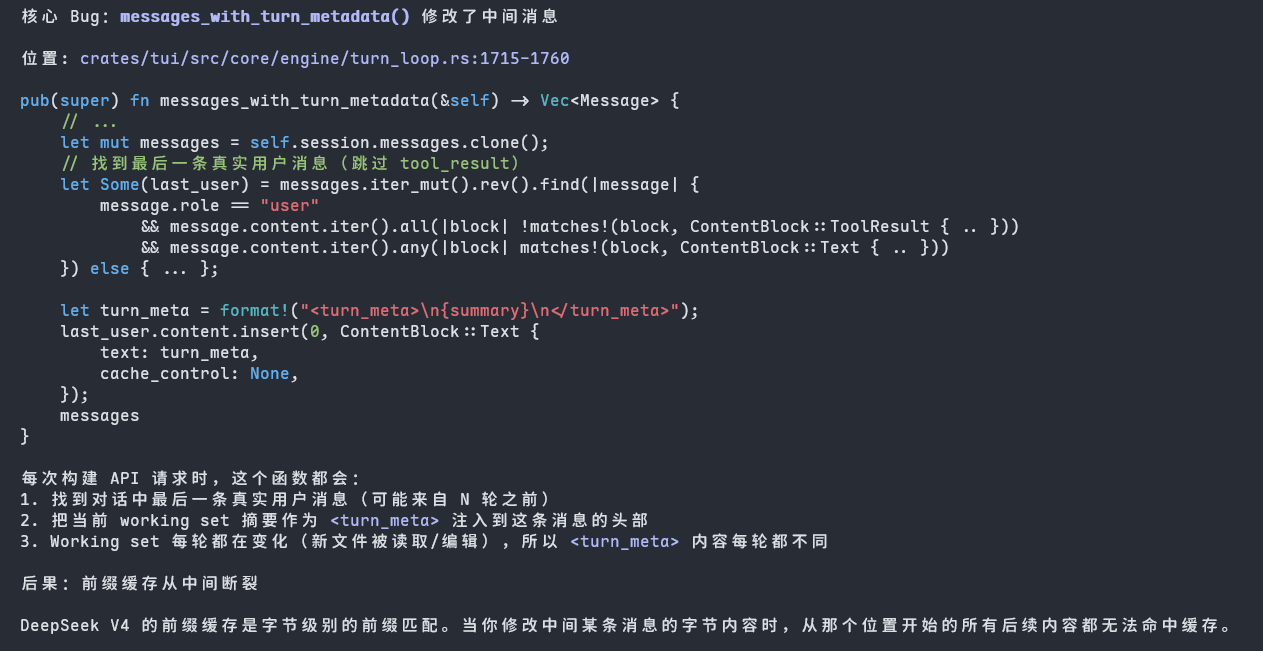
修复方向如下

总结与展望
没有官方支持和针对性的指令优化可能是这个项目当前最大的短板,但我仍看好DeepSeek-TUI。现在的项目社区正处于极度活跃的“极客阶段”,项目几乎以小时级在迭代,大量开发者都在贡献力量。这种“发现问题 -> 社区共研 -> 快速修复”的生命力,正是开源精神最迷人的地方。期待DeepSeek-TUI站上巅峰的那一天。